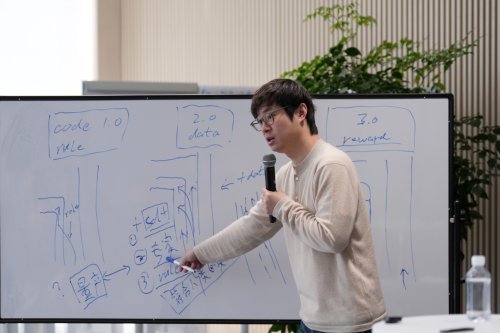
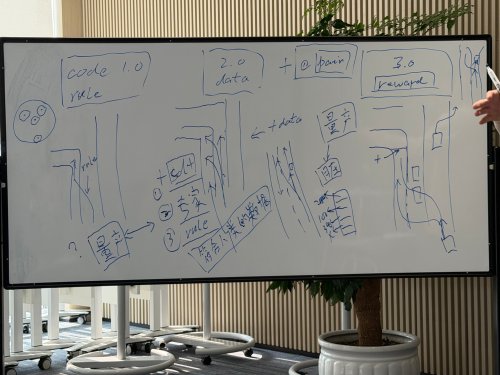
NIO says its intelligent driving code and models are about 95% shared across two platforms. Ahead of NIO’s official rollout of its new intelligent driving system and the NIO World Model (NWM) 2.0, ChinaEV Home was invited to a closed-door media briefing on NIO’s intelligent driving held in Caohejing, Shanghai. NIO headquarters in Caohejing, Shanghai The briefing was attended by Ren Shaoqing, NIO Vice President and Head of Intelligent Driving R&D, and She Xiaoli, Head of Product System for NIO Intelligent Driving R&D. Ren Shaoqing opened by distilling the past six months into two points. First, the overall development and iteration paradigm has shifted significantly. The team went through a “painful phase,” but the way it solves problems is now clearly different from the mid-year version. Second, the main-selling models on the second-generation platform have largely reached EOP (End of Production) and now fully adopt NIO’s in-house intelligent driving chip. Meanwhile, the iteration cadence of the in-house-chip platform has been compressed to about a two-week cycle in step with the mainline 4-Orin platform. NIO also says the in-house-chip code and models are now about 95% shared across the two platforms, and updates will be pushed to users on both sides in January. NIO Vice President and Chief Expert for Autonomous Driving R&D, Ren Shaoqing In our previous article, we already mapped out the core narrative of this briefing, aiming to explain it in a more “non-technical” way. In this piece, we focus on the Q&A session, pulling out the questions and answers that carry more information and are closer to the details and judgments people care about most. I. Simulator, World Model, and Evaluation Framework Q: If the simulator encounters an intersection it has never seen before, how do you handle it? Ren Shaoqing: In Code 1.0, to handle an intersection you first needed to know what the intersection looks like, and what cases and code issues show up there. In Code 2.0, beyond knowing what the intersection looks like, you also needed to collect expert driving trajectories at that intersection to train the model to solve the problem. In Code 3.0, the core is to use a simulation environment plus reinforcement learning so the system can leverage existing foundational data to learn how to handle unseen intersections on its own, by building a simulated world that can accurately generate dynamic interactive scenarios. Ren Shaoqing briefing the group Q: What does this approach specifically require? Ren Shaoqing: Our simulator is relatively simple. The real world has all kinds of scenarios. Take Chongqing, for example. We find a few special entrances, our selection rules are automated, and then we put them into the simulator and the world model. This simulator is built on top of the world model. Once we put those intersections in, the static part is there, because if a vehicle scans and drives through once, trajectory by trajectory, building the static intersection is easy. The second part is what to do about dynamics. My car in the original data might have driven in one particular way, but in the simulator it can’t always follow that same trajectory. For example, if we want the car to learn how to drive in congestion, we will create more virtual cars, or “agents.” These agents must be dynamic, not “dead” vehicles frozen in place. So we model them with a world-model approach, meaning an overall model that allows them to interact with our vehicle. My own vehicle may have a starting point from the collected data, and the rest of the vehicles will move accordingly. For instance, after my vehicle moves for 0.1 seconds, the other vehicles will move too. A world model builds a larger simulator, and then we let it learn inside that environment. Q: How do you judge whether the simulated scenarios are sufficient? Do you look at the number of intersections or mileage, or are there other evaluation methods? What should this evaluation include? Ren Shaoqing: Evaluation mainly has two parts. First is the static part, which includes the richness or coverage of scenarios. We build static scenes and compute the similarity between scenes. Similarity, to some extent, is distance. We believe the existing raw data already provides enough coverage. On that basis, we can set a distance threshold in feature space and fill in scenarios that meet the criteria, so we can cover and “fill” the whole dataset. Dynamics are more complex. On the one hand, we need to build a distribution generator based on the world model. On the other hand, we need to evaluate how different the diversity of dynamically generated simulated scenarios is from the diversity in the real world, which involves more complex work. Overall, the evaluation framework consists of these two parts: static and dynamic. NIO Head of Intelligent Driving R&D Product System, She Xiaoli II. Human–Machine Co-Driving, Paired Data, and the Closed-Loop Question Q: During reinforcement learning, the vehicle side will generate “good” and “bad” driving data. Can this form a closed loop and continuously feed back into the model for iterative optimization? For example, can good or bad system behavior be used in real time for model updates? Ren Shaoqing: That’s a very good question. We haven’t fully implemented this closed loop yet. The version everyone experienced today is, in our view, still at an early stage under this new paradigm, but it has already shown several advantages. One is the use of paired data. For example, the human–machine co-driving mode everyone experienced yesterday can generate more pairs. Beyond methods like PPO (Proximal Policy Optimization), reinforcement learning can also use paired data, essentially “this is good, this is bad,” making the algorithm prefer better behaviors and avoid worse ones. Q: Now that co-driving is enabled, in a co-driving scenario should the system follow the human’s actions? Ren Shaoqing: After a user enters co-driving, two trajectories are produced: one is the trajectory originally planned by the model, and the other is the trajectory after the person turns the steering wheel. Why do we do co-driving? Because the previous takeover experience wasn’t very good. After turning the steering wheel you would exit, then you had to straighten the car before you could restart intelligent driving, so the process wasn’t great. Now, because the model is stronger, it can take over at any time. The first benefit from the user’s perspective is that you don’t need to exit, straighten, and press a button again. You just make one steering input. It goes from three actions to one, so the user experience is better. Second, the positive and negative samples are more useful to us. One is the original planned trajectory, and the other is the user takeover. Because the user takeover time and interruption time are much shorter than before, we can capture, within a very short window, how the model planned and how the user moved, and use them together in the subsequent rendering process. Q: What if the driver intervenes via the brake pedal? What about acceleration? Ren Shaoqing: Currently, braking will interrupt co-driving; acceleration will not. Q: What about using the physical button? Ren Shaoqing: The button will not interrupt it. Q: On co-driving, if I intervene on the road but that specific scenario does not exist in the simulator, does that mean the current co-driving data cannot go back into the simulator to form a closed loop? In the future, can it automatically generate the corresponding scene state in the simulator once intervention happens, so the data can be used? Ren Shaoqing: After co-driving is pushed, it brings two kinds of value. First, the real driving trajectory generated by the user intervention will be recorded. If this trajectory is better than the system’s original plan, it can be used as training data, and it can also serve as a criterion for our reward. For example, why didn’t the model choose the better trajectory driven by the human? This helps us iterate the reward. Second, the human-driven trajectory itself will also be added into the pre-training dataset, so the model can learn more human driving behavior. NIO Vice President and Chief Expert for Autonomous Driving R&D, Ren Shaoqing III. Industry Stage, High-Impact Scenarios, and Training Cost Q: Reinforcement training and world models have been discussed by many companies since April or even earlier. From your perspective, how many systems in China have truly entered the 3.0 stage? Ren Shaoqing: In China, there is currently only one system that has achieved full reinforcement learning, and that is ours. Q: In this version, which scenarios do you think benefit the most from the new-stage paradigm? Ren Shaoqing: For us, it’s lane drifting and intersection handling, including cutting in. These see significant gains compared with previous versions. Q: After switching to the reinforcement-learning version, did training costs go up or down versus before? Ren Shaoqing: Compared with the previous version, training cost for our current version is relatively low within the industry, roughly about one-fifth to one-tenth of peers. In the next version, we will scale up the data size. IV. Where to Draw the Line Between “World Model” and Reinforcement Learning Q: Xiaomi recently released a new version and mentioned introducing reinforcement-learning training and a world model. Do different companies define “world model” differently? Huawei is also talking about it. It seems everyone is discussing world models now. Ren Shaoqing: Different companies may define and understand “world models” differently. We focus more on the upper bound of its capability in the real world, because existing language models and their variants can be inaccurate in quantitative understanding of physical quantities like speed, distance, and safety. The root cause is that training data is mostly text, with relatively little video. Language models may incorporate more video and data in the future, but that is the current situation. In summary, world models have three main uses: first, AIGC video generation, such as Sora; second, as a simulator or data-generation tool; and third, as a foundation model that improves the underlying capabilities of on-device models. World models are still being explored, and we are continuing to make them better.































































































Overall it is quite impressive but still feels more like a promotional piece than a deep technical analysis
Moving away from heavy reliance on manual data feels like the right direction but it is unclear how stable it will be in complex scenarios
The article is easy to follow and the AI world model approach sounds promising but it still needs real world validation