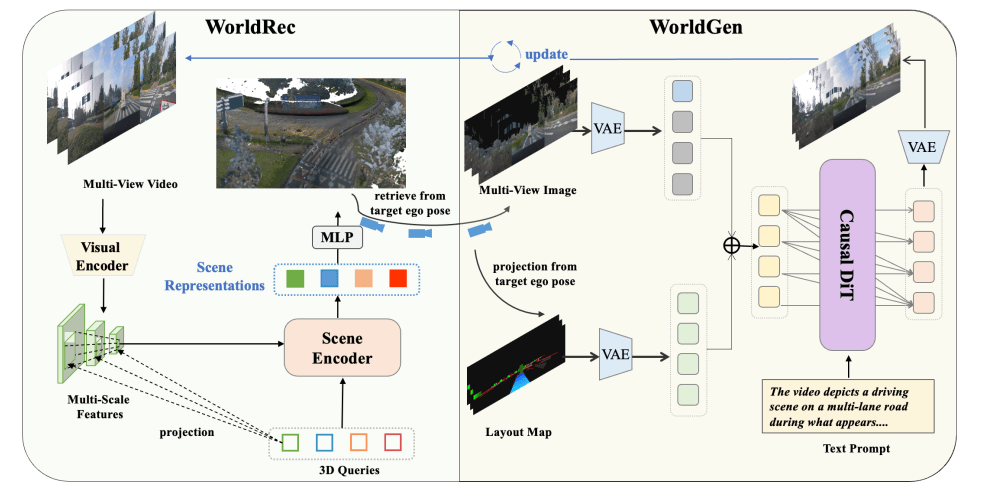
On May 26, Xiaomi Auto officially unveiled its new Xiaomi Auto World Model framework, marking the company’s first systematic public disclosure of its autonomous driving world-model technology roadmap. Over the past several years, competition in the assisted-driving industry has primarily centered on perception capabilities, including LiDAR, cameras, BEV perception and end-to-end AI models. Currently, the industry’s mainstream world-model approaches generally follow two technical paths. One focuses on “reconstruction,” using multi-view inputs to restore highly accurate 3D scenes, while the other emphasizes “generation,” leveraging AI to predict future visual scenarios. The former offers greater stability but limited imagination capability, while the latter is more flexible but prone to distortion. Workflows of ‘WorldRec’ and ‘WorldGen’ Xiaomi’s latest approach combines both routes into a unified architecture. According to the company, the Xiaomi Auto World Model deeply integrates a 3D reconstruction module called WorldRec with a video-generation module named WorldGen. The reconstruction system provides stable three-dimensional geometric structures, while the generation system supplements unobserved areas and predicts future scenarios, reducing long-sequence drift issues during generation. From an industry perspective, world models have become one of the hottest areas in assisted-driving development over the past year. Since the beginning of this year, automakers including Tesla, NIO and XPeng have all accelerated world-model development, though their technical approaches differ significantly. Tesla has focused more on neural world simulation, XPeng has adopted a video-diffusion generative world-model route to support VLA, while NIO emphasizes imagination-based reconstruction and scenario reasoning. Compared with traditional rule-based logic, the key evolution of world models lies in enabling vehicles to move beyond merely “recognizing scenarios” toward actively “predicting scenarios.” Xiaomi stated that its model has already achieved state-of-the-art (SOTA) performance on public datasets including Waymo and nuScenes benchmarks. The generative model reportedly supports video generation of up to one minute and has already been deployed across three major application areas: synthetic data generation, simulation testing and intelligent cockpit systems. For synthetic data generation alone, Xiaomi said the framework has already produced more than 100,000 high-quality video clips for training assisted-driving perception models. Comparison of scene reconstruction results of different algorithms: GT, Xiaomi, DGGT, and STORM Notably, Xiaomi disclosed the technology amid a period of tightening regulatory oversight across China’s intelligent driving sector. China’s MIIT recently launched its 2026 nationwide NEV safety inspection campaign, which specifically identified combined assisted-driving system safety and extreme-condition operational risks as key regulatory focus areas. As industry attention increasingly shifts toward assisted-driving safety, improving the ability to handle long-tail risk scenarios is becoming a central challenge for automakers across the sector.