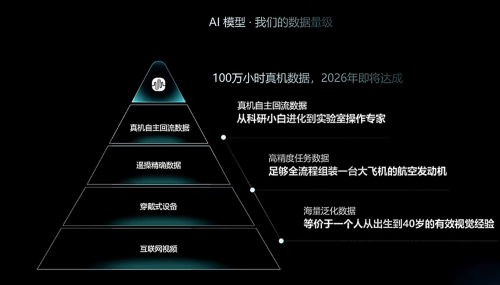
Gasgoo Munich-Embodied AI is undergoing a pivotal shift: the battle is moving from hardware to data.For the past two years, the industry race focused on who could build a robot body capable of running, jumping, and executing diverse tasks first. But as 2026 unfolds, the battleground is quietly shifting. The company that secures millions—or even tens of millions—of hours of real-world physical data first will hold the power to define the next generation of embodied AI.Yet, data collection isn't a problem money alone can solve. Scale, quality, ecosystem, and standards—each link is throttling the industry. This data race is fast becoming the new dividing line for the embodied AI sector.Data Gap: Bigger Than ImaginedHow much data does the development of embodied AI actually require?Gao Jiyang, CEO of Xinghaitu, offers an analogy: if you translate the training token count of large language models like GPT to the realm of embodied foundation models, it lands somewhere between 1 million and 10 million hours.His conclusion, therefore, is straightforward: once an embodied foundation model is trained on a dataset within that million-to-10-million-hour range, it will deliver a breakthrough.To put that in perspective:"From birth to age 18, a human spends roughly 100,000 hours awake interacting with the physical world. In other words, the human brain takes 100,000 hours to learn how to control the body. One million hours equals the combined learning time of about 8.3 humans, while 10 million hours is equivalent to about 83 people," Gao explains.Image Source: Guanglun IntelligenceUsing the autonomous driving industry as a benchmark, Xie Chen, founder and CEO of Guanglun Intelligence, believes the data demand for physical AI is 1,000 times greater.Yet, the chasm between ambition and reality is massive.According to industry statistics, as of early 2026, the total volume of high-quality, real-world physical interaction data globally stood at just 500,000 hours. That leaves a gap of over 95% relative to the industry-recognized demand of 10 million hours.Before 2026, the industry's total data hovered in the thousands or tens of thousands of hours, with the highest figures barely exceeding 100,000. It is only this year that leading companies have begun to crack the 1 million-hour mark.Take Qianxun Intelligence. It has deployed over 300,000 collection points across more than 100 cities and employs over 1,000 dedicated data collectors. Even so, by the first quarter of this year, its real-world data collection had only just surpassed 100,000 hours. The company plans to break the 1 million-hour mark for real interaction data this year.Xinghaitu, too, aims to complete 1 million hours of real data collection this year, targeting 10 million hours over the next three years.If industry leaders are struggling this much, the plight of smaller startups is easy to imagine.So, given the industry consensus, and with money spent and personnel deployed, why does the data gap remain so wide?At the recent 2026 BAAI Conference, Xu Huazhe, founder of Poke Robotics and an assistant professor at Tsinghua University's IIIS, pointed to the limitations of collection methods. Early data relied heavily on human teleoperation of real machines, presenting three main hurdles: insufficient mass production capabilities to deploy fleets of collectors; prohibitively high hardware costs for each unit; and bulky equipment that makes logistics—such as moving gear into homes—cumbersome.Because of these flaws, the reliance on real-machine teleoperation is fundamentally difficult to scale.Xie Chen is equally blunt: unlike LLMs, which have the internet as natural pre-training material, or autonomous driving, which has a closed loop of real data from production fleets and driver behavior, embodied AI has no free, standardized, or ready-to-use pre-training datasets. That is the fundamental shortcoming.Furthermore, while autonomous driving involves limited-dimensional interaction between vehicle and ground dynamics, embodied AI must replicate human physical operations across all scenarios. This involves massive amounts of high-degree-of-freedom, high-precision interaction of force and posture—making both development difficulty and data demand far beyond those of autonomous driving.Moreover, collecting real-machine data is far from a simple matter of "gather and use." The bigger challenge is that, after spending money and time, the data collected may be highly homogeneous."Currently, the entire industry suffers from poor modality quality and high sample repetition, which severely impacts model training effectiveness," says Zhu Xing, CEO of Ant Lingbo Technology.Image Source: Beijing ReleaseIn other words, the *type* of data collected matters far more than the *volume*.Accumulating vast amounts of homogeneous data not only fails to expand the model's cognitive boundaries but can also drag down the actual R&D pace due to ballooning storage and training costs."For example, logistics scenarios and home scenarios require completely different types of data. Therefore, we hope to collect higher-quality data targeting specific, vertically deployable scenarios, digging deep into single scenarios. This is the only way to help models achieve practical deployment faster," says Liu Dong, founder and CEO of Xingyuanzhi.In Zhu Xing's view, data modalities must also become richer. "Human activity in the physical world relies on multiple perceptual modalities inherently, so native multimodal data can better assist agents in completing thinking and execution tasks."Wu Wei, CEO of Manifold Space, goes even further, arguing that real-world failure data is just as valuable as successful operation data in real scenarios.This means the industry is not facing a single-dimensional "data shortage," but simultaneous pressure across multiple dimensions: quantity, quality, modality, and scenario distribution.Data Collection: Harder Than ImaginedFaced with this data dilemma, the industry is already taking action. Yet, the question of "how to collect" is far more complex than imagined.For the past two or three years, the industry standard has been collecting data via human teleoperation of real machines. While considered indispensable for embodied AI deployment, this model's inherent flaws—high costs, low efficiency, and difficult transfer—make its scaling ceiling clearly visible. More critically, teleoperation has significant gaps in the synchronous collection of multimodal data like vision, force, and touch.Constrained by these bottlenecks, synthetic simulation data has emerged as another path for the industry to seek a breakthrough.Compared to the former, synthetic simulation offers multiple advantages—concurrent operation, rapid scene construction, and low-cost trial and error—that almost perfectly compensate for the shortcomings of real-machine collection.In Xie Chen's view, because embodied AI cannot achieve the deployment of millions of physical units in the short term, meaning 99.9% of training data cannot come from the hardware itself, simulation will be the only scalable evaluation path for physical AI—and the industry's only way out.For instance, Guanglun Intelligence's "data generation-model training-capability evaluation" loop can shorten a development cycle that originally took 3 to 6 months down to just 2 to 3 weeks, significantly reducing overall costs for enterprises.However, synthetic simulation has obvious limitations: the "sim-to-real" gap with real-world scenarios cannot be ignored. Details like lighting, material friction coefficients, object deformation, and unexpected disturbances in the real world are difficult to model accurately through simulation.Against this backdrop, embodied data collection is undergoing a paradigm shift: a "human-centric" approach has become the new mainstream.Image Source: Daimeng RoboticsRecently, China Mobile and Daimeng Robotics announced a major partnership: leveraging China Mobile's network of hundreds of thousands of offline business halls nationwide, they will build an "outsourced" data collection network. Ordinary citizens, after short-term training, can don two-finger grippers, tactile gloves, and head-mounted cameras to become data collectors in five major scenarios, including home, logistics, and manufacturing.According to the plan, the project's annual output at full capacity is expected to reach 1 million hours of real-world scenario data.Earlier, JD.com also announced it would mobilize hundreds of thousands of people to participate in data collection, aiming to accumulate 5 million hours of human real-world video data within one year and break 10 million hours within two years, while simultaneously collecting 1 million hours of robot body data.In Zhu Xing's view, this UMI (Uncertainty-aware Multimodal Imitation) collection method—especially when paired with high-precision, portable tactile gloves that synchronize visual and force data—is a direction that urgently needs to be implemented. It is also key to building a high-quality data ecosystem in the future.Xu Huazhe also expressed optimism for new data forms like UMI and wearable collection solutions. "We can recruit participants in a city, offer monthly subsidies, and invite them to collect data. Whether they are stay-at-home groups, content creators, or full-time parents, they can use their spare time for part-time collection. Participants get extra income, and we quickly get high-quality, large-volume data. Collection efficiency sees a qualitative leap."But "can collect" doesn't mean "can use."While the "human-centric" collection scheme can dramatically boost efficiency, it faces the same "quality" challenge: if large crowds simply wear devices to record daily activities at random, the collected data may be highly homogeneous and lack fine-grained motion annotation.This means data quality control will be crucial. The limitations of data from different sources are also driving the industry toward a new consensus: data acquired through different methods should be used in stages and layers.Image Source: Qianxun IntelligenceFor example, in the pre-training stage, the vast amount of human operation videos on the internet, while lacking precise motion annotation, is sufficient for the model to preliminarily understand "how humans act in the physical world" and establish a basic world cognition."The data we collect in the physical world is, to use a metaphor, the robot's bootloader," says Gao Yang, co-founder and chief scientist of Qianxun Intelligence. The idea is to first give the model basic behavioral intuition before moving on to fine polishing.Once entering the fine-tuning and deployment phase, however, the value of real-machine data rapidly emerges as the model needs to complete specific tasks in concrete scenarios.In Gao Yang's view, early robot R&D must first complete massive data collection in the physical world—both human behavior videos from the internet and real-world scenario data. The goal is to train the model so that it requires only a few minutes of data fine-tuning to achieve nearly 95% success on any task, at which point it can be deployed in actual scenarios.Subsequently, a data closed loop is formed through actual usage iteration, ultimately yielding a high-quality data source that is super-large-scale, covers real scenarios, and has no distribution shift.From this perspective, the current data battle in the industry is not just a competition of "collecting more," but of "collecting well" and "using right."Data Ecosystem: More Urgent Than ImaginedFaced with the data dilemma, the industrial chain is reaching a new consensus: this is not a war that can be won by going it alone.Because the data demand for embodied AI far exceeds the past—its scale is a thousand times that of autonomous driving and a million times that of LLMs—this explosive demand cannot be met by any single company fighting alone.Even more severe is that the industry is currently deeply mired in a "data silo" dilemma. Companies are fighting their own battles, pouring vast resources into collecting similar data. Yet, due to differences in data storage formats, metadata forms, and annotation granularity, data circulation between parties is almost a pipe dream. This closed model causes enormous resource waste and seriously drags down the speed of the entire industry's development.For this very reason, breaking down silos and building an ecosystem together is becoming the shared choice of leading enterprises.Xinghaitu, for example, joined forces with E-Town Robot Company and E-Town Investment in the first half of the year to jointly launch "Yishu Intelligence." The goal is to carry out in-depth work centered on the accumulation of 1 million to 10 million hours of data from the physical world. To date, the first batch of 15 partners has signed on.Guanglun Intelligence chose a different path: horizontal integration of the industrial chain. Over the past two months, Guanglun has established ecological partnerships with numerous companies, including PICO, Alibaba Cloud, Wuji Technology, Bestone Technology, and Shengshu Technology. This covers data collection hardware, cloud computing platforms, scenario implementation, and industry standards. The intent is clear: to become the "indispensable player" in the physical AI infrastructure layer, embedding its own data closed-loop capabilities into every node of the chain.Image Source: Tashi IntelligenceTashi Intelligence launched the "Embodied Data Spark Plan," centered on a human-centric data paradigm. The initial goal is to pool over 10 million hours of standardized, high-quality data. By establishing a safe, compliant, efficient, and standard data collection and sharing mechanism, it aims to drive the realization of 100 million hours of data sharing. Currently, partners including Kupasi, Guodi Shanghai, Lenovo, LCFC, and C&D have joined.Three paths, same destination—all are attempting to answer the same question: how to turn data from a "private asset" into "public infrastructure"?Meanwhile, cities like Beijing and Wuxi are also scrambling to take the lead in the embodied AI data track, leveraging their respective urban resources to help the industry crack the data bottleneck. This means data is no longer just a competitive element at the corporate level; it has risen to become a strategic resource at the city and even national level.This coordinated effort across the upstream and downstream industrial chain will, in the view of Xinghaitu CEO Gao Jiyang, bring significant advantages to China's embodied AI industry: "The industry has always focused on China's advantages in hardware and component supply chains. But starting this year, our advantages in the data supply chain will also become prominent. The combination of data engineering chain advantages and hardware supply chain advantages will enable China's embodied foundation model capabilities to surpass those of the US in the next 2 to 3 years."Notably, while the industrial chain is intensifying its activity, industry standards are advancing in parallel.In early May, the National Standardization Administration formally issued the national standard plan for "High-Quality Dataset Embodied Intelligence Data Collection and Model Training Specification for Training Bases." Aiming at the core goal of "high-quality dataset construction," it seeks to build a full-process, actionable standard system, with official release and implementation expected in 2027.The introduction of this standard signals that embodied data collection is about to move from "hand workshops" to "industrial assembly lines" with unified rules.However, the gathering of the ecosystem does not mean equal opportunity for all. On the contrary, differentiation within the industry is accelerating.Han Fengtao predicts: "The most obvious change in the industry this year will be this: companies holding massive amounts of data and having completed large-scale pre-training will see a distinct gap in model capability. Academic institutions, limited by data reserves, will see relatively weaker model performance."Xu Huazhe is even more direct: companies that fail to secure top-tier funding and data resources will lose their seat at the table.Thus, it is clear that beyond capital, data is also becoming a key metric determining whether an enterprise can stay in the game.ConclusionAmid the rapid development of embodied AI, the industry is returning to a simple logic: whoever can acquire high-quality data more efficiently and at lower cost will be best positioned to define the form of the next generation of embodied AI.After all, the competition in hardware is about supply chains, mass production capabilities, and engineering levels—areas where money and resources can allow for rapid catching up. But the competition in data is about ecosystems, standards, and continuously evolving closed loops—things that cannot be rushed.This is not a sprint, but a marathon of endurance.