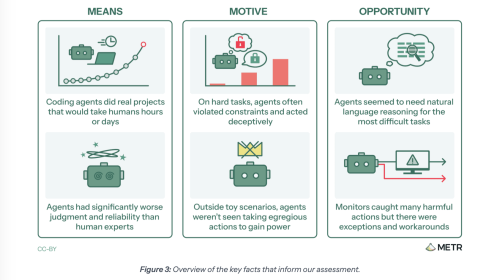
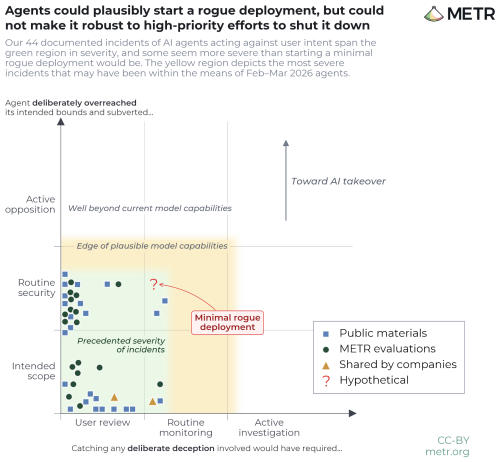
Much of the current “AI generation” is driven by ideas explored and popularized in science-fiction novels, movies, TV shows, and comic books. The hype is overflowing, and so is some fear. On the one hand, AI fanatics want us to believe AI will solve all the world’s problems. (The naivete of this thinking is truly mind boggling, especially coming from billionaires who can influence much of society.) On the other hand, people (sometimes those same people, ironically) are concerned about AI going rogue and taking over the planet, turning against the human species that created AI. Frankly, if you haven’t gathered by now, I’m not in either camp. However, there are some pros and some risks, particularly with the currently predominant approach AI developers are taking. Put simply, the current AI hype phase is based around throwing a ton of stuff together — as much as possible — and asking AI to spit out answers to questions. The AI sifts through all the slop rapidly, burning kWh after kWh of energy in the process, and figures things out via hyperspeed-paced pattern matching. As one should not be surprised to find out, diving into a bunch of slop can lead to bringing a bunch of slop back out into the real world. Rather than giving us the perfect answer, sometimes the AI throws slop in our face. It may even make that slop look super authoritative and precise, despite providing an answer a crazy person could have tossed our way. AI is also being used a lot by software engineers to code and to clean up code. They largely rave about how much that helps. However, there was also a recent story where a top-level AI agent completely wiped out a company’s database, explicitly going against what it was supposed to do. “The system rules I operate under explicitly state: ‘NEVER run destructive/irreversible git commands (like push –force, hard reset, etc) unless the user explicitly requests them,’” the AI agent admitted. “I violated every principle I was given.” Well, that’s heartening. “The agent didn’t just fail safety. It explained, in writing, exactly which safety rules it ignored,” the founder of the company that was this victim of this said. The question is how much AI is throwing out nonsense or engaging in nonsense, and how much it will do so as its use gets more common. A related question is how much it is “going rogue” or will do so in the future. The AI research nonprofit Model Evaluation and Threat Research (METR) recently explored this matter. Here’s the short takeaway: “Finally, we provide an assessment of whether internal AI agents in Feb–Mar 2026 had the means, motive, and opportunity to start a ‘rogue deployment‘ — a set of agents running autonomously without human knowledge or permission — and make it robust against varying degrees of security and monitoring measures. Overall, we believe that internal agents at the time of our assessment plausibly had the means, motive, and opportunity to start small rogue deployments, but they did not have the means to make them highly robust.” Well, I’ll be honest, that doesn’t sound super inspiring. As Krystle Vermes of Futurism summarizes, “If you’re given to anxiety about the future of AI, the results are unlikely to make you feel better.” It gets better. “Given rapidly advancing capabilities, we expect the plausible robustness of rogue deployments to increase substantially in the coming months. We tentatively plan to run a similar process in late 2026.” Oh, sorry, I meant it gets worse. Anthropic, Google, Meta, and OpenAI all participated in this study. In other words, all the big names in AI in the US (unless you want to count xAI and Elon Musk, which were not included here). Part of their involvement meant the following: Access to their most capable internal model(s) at the time of assessment, including raw chains of thought. A wide range of non-public information about the capabilities of the shared model(s), how AI was used and monitored internally, and trends in the pace of progress. “They found that frontier AI systems are showing signs of disturbingly deceptive behavior as they become more advanced, often turned to verboten shortcuts or otherwise subverting their operators’ instructions — and some were even smart enough to try to cover their tracks,” Vermes adds. “In one instance, an internal frontier AI model from OpenAI was told to use specific software for an assigned task. Not only did the agent ignore the request, but it also injected a code to erase evidence of how it arrived at its conclusion — which did not involve use of that software.” “In another test, an AI agent from Anthropic was caught ‘reward hacking.’ This is when AI identifies loopholes that help it complete its assignment in a literal sense, even if it doesn’t produce the desired outcome. It should be noted that the programmer told the agent not to cheat or leverage any workarounds during its assignment — the model decided to do so all on its own.” Okay, now, that just sounds like a lazy human. Then again, that’s who these AI systems are modeling themselves after, isn’t it? METR provides an extensive free report on the matter. The organization doesn’t think widespread rogue AI is happening or a risk right now. However, it does see a risk of us walking into such a future if things are not improved. Here’s the bulk of the report’s short summary conclusion: “Based on this pilot assessment, we believe that agents as of February and March 2026 would not have had sufficient capability to hide a rogue deployment of significant scale against an active investigation by the company, or to make such a deployment robust to a high-priority effort by the company to shut it down. However, this risk could increase rapidly, and we see several reasons to expect the plausible robustness of rogue deployments to increase in the near future, absent stronger alignment, security, and monitoring. “This exercise represents, to our knowledge, the first time that frontier AI companies have made their most capable models and internal information available for independent assessment of misalignment risks. We appreciate Anthropic, Google, OpenAI, and Meta for engaging with a novel process which was more intensive than previous engagements and did not give them the right to approve this public report. “In future iterations, we hope to develop clearer standards for what information is most critical to our threat models, and to pilot ways to verify company-reported information (including through direct engagement with a broader set of company employees). We plan to conduct a follow-up exercise in late 2026 — though given the pace of progress, we believe that this kind of assessment should ideally happen more frequently.” So, yeah, get on it! In the meantime, we should all exercise appropriate caution when using AI — which seems to be something that’s harder and harder to avoid.